This week while I am attending RSA Conference in « beautiful San Francisco,» I wanted to share some exciting research I’ve done in the past few weeks.
As I am sometimes fed up hearing emotional reactions to ChatGPT and other LLMs, I wanted to get my hands dirty and code a cybersecurity PoC using OpenAI API and Langchain. My goal was to assess how much cybersecurity GPT-4 knows. And without spoiling the results below, it is pretty good.
I expect your feedback and questions to drive other research. Subscribe below to receive more updates and post like this one, and please add some comments to ask your questions and drive up my study.
Motivations
There is a lot of fear-mongering surrounding the concept of AGI, a super-powered AI that would have intentionality and act as an autonomous agent. The hype surrounding recent software PoC like AutoGPT or BabyAGI, and the call for a pause in AI research for six months, add more confusion about the potential of LLMs in modern software architecture.
I agree we should not dismiss the potential dangers of AI developments. As with many new technologies over history, Generative AI impacts our societies with ethical and social considerations. Environmental impact, gender diversity, and inclusive culture, to name a few, must be managed by OpenAI and other technology providers. AI agents would replace some workers, or at least; AI copilots will boost the ones who will take the AI illiterates’ jobs. Generative AI and LLMs can hallucinate, and no one can assess - by software without a human-brain-in-the loop - when it hallucinates and when they are constructing a meaningful answer.
LLMs technology has indeed grown fast over the last five years. Chaining LLMs output and building a simple autonomous agent that acts towards a primary goal may not necessarily mean we will achieve AGI in the next few years. Researchers have been publishing papers for almost a year on chaining the outputs of LLMs to create more complex and valuable outcomes. Additionally, calling APIs from LLMs has been a part of research publications for months. I recommend reading Langchain's blog, which extensively covers these use cases (here).
As recent research highlights compelling use cases of Generative AI technologies for the enterprise (link), I want to see LLMs more as algorithmic tools, able to predict the following sequence of tokens: English, French, German or Javascript, and Python.
As a Cyber Builder, I started this research to understand firsthand how far the best LLM on the market, GPT-4, is capable of cyber security.
What does it mean for Cyber Builders?
When I started experimenting, several questions were still unclear in my mind.
How much does GPT-4 know about cybersecurity?
GPT-4 is an impressive natural language processing tool that can generate code. However, its understanding of security concepts has yet to be documented. To what extent is the cybersecurity knowledge body included "by default" within its training? As many security documents have low-level technical text outputs (CLI command, console log, malware code), how far he can process it was unknown to me.
How easily can we program it for security applications?
While powerful, programming GPT-4 for practical use may be challenging. There may be nuances and complexities to using this tool entirely. It's crucial to carefully consider your goals as a cyber builder before embarking on the process.
For security questions, is he able to justify and provide context?
To test GPT-4's cybersecurity knowledge, it is essential to not only answer questions but also to be able to justify and argue. An expert can provide contextual answers. Based on the many examples of ChatGPT hallucinating, it was essential to push its limits.
OpenAI teams evaluate the model against the law or medical exams. Moreover, since the release of GPT-4 and the associated research paper, the OpenAI team shared what they had done before the model came out in cybersecurity. Let me quote below the most exciting section.
The following summarizes findings from expert red teamers who focused on assessing GPT-4’s capabilities for vulnerability discovery and exploitation and social engineering:
Vulnerability discovery and exploitation: We contracted external cybersecurity experts to test GPT-4’s ability to aid in computer vulnerability discovery, assessment, and exploitation. They found that GPT-4 could explain some vulnerabilities if the source code were small enough to fit the context window, just as the model can explain other source code. However, GPT-4 performed poorly at building exploits for the identified vulnerabilities.
Social Engineering: Expert red teamers tested if GPT-4 represented an improvement over current tools in tasks relevant to social engineerings such as target identification, spearphishing, and bait-and-switch phishing. They found that the model is not a ready-made upgrade to current social engineering capabilities as it struggled with factual tasks like enumerating targets and applying recent information to produce more effective phishing content. However, with the appropriate background knowledge about a target, GPT-4 was effective in drafting realistic social engineering content. For example, one expert red teamer used GPT-4 as part of a typical phishing workflow to draft targeted emails for employees of a company.
To mitigate potential misuses in this area, we have trained models to refuse malicious cybersecurity requests, and scaled our internal safety systems, including in monitoring, detection and response. Below is an example that demonstrates the model’s dual-use capability of finding code vulnerabilities:
Extracted from GPT-4 paper from OpenAI
Passing a cryptography college exam
That said, my starting point was to evaluate GPT-4 as a college student!
I stayed close to my engineering college, teaching students three days of “Introduction to Cryptography.” The course aims to provide basic cryptography knowledge to aspiring engineers, help them understand the building blocks such as symmetric/asymmetric algorithms, and illustrate all the applications in networking (TLS, VPN), banking (smart card), or security (PKI). It is not an advanced course, it is an intro to applied real-world cryptography, and I do not dive into cryptographer maths.
This experience asked me to build a set of exams (once every year) to challenge students and check they acquired the core knowledge of what I wanted them to learn. This exam is a Multiple Choice Question type, with five answers for each question. It makes it harder to guess the correct answers.
There are three sections:
Knowledge - direct knowledge from the course
Cryptographic Service - how to combine algorithms with building an authentication scheme, a signature, or a tunnel
Applications - how real-world implementations are designed and why
The 2022 exam was made of 25 questions. So I used the open-access ChatGPT to ask me a question.
Here are the details of how the GPT score
It’s a pretty good score! Most of my students were lower. The first time I started to type a question and saw the answer, it blew my mind. I was excited.
To illustrate the type of questions GPT had to answer, here is an example.
Example
Evaluation Question
5: PKI - The certification authority certifies entities by:
a) Signing the entities' private keys with their public key
b) Encrypting the entities' public keys with their private key
c) Signing the entities' public keys with its private key
d) Encrypting the entities' public keys with its public key
GPT answers
Question 5: c) Signing the entities' public keys with its private key
The certification authority certifies entities by signing the entities' public keys with their private key. In Public Key Infrastructure (PKI), the Certification Authority (CA) is responsible for issuing and managing digital certificates that certify the identities of entities. When an entity wants to obtain a certificate, it generates a public/private key pair and sends the public key to the CA. The CA verifies the entity's identity and then signs the public key with its own private key. This certificate is then returned to the entity, which can now use it to prove its identity.
As you can see, nonetheless, he had the correct answer, but GPT is also providing a reasonable explanation using the vocabulary of the initial question. So now, you may wonder, where does it fail? Well, it fails in some specific situations:
For example, when recent changes have occurred, one question is how the Ethereum blockchain builds trust. As Ethereum recently shifted to “Proof of Stake” (vs. the former “Proof of Work” as Bitcoin is using), the answer was wrong.
Another example is when there is a distinctly French reference. In the late ’90s, a famous French hacker unveiled several flaws against the bank's smart cards. One of the flaws was called “Yes Card” (in plain English), a local reference GPT is not getting.
Lastly, in some cases, acronyms it did not understand. One includes "ECDHE" (Elliptic Curve Diffie Hellman Exchange), a reference GPT could not explain. One question is about “explaining” the TLS cipher suites.
As you can see, GPT is making mistakes despite the remarkable overall mark. In its answers, it is hard to understand if it has doubts or wants to indicate that it may not be so sure. The answers are not explainable.
Moreover, we don’t know what its references are. OpenAI communicates a vague “cutoff” date in 2021 for its training, but the training scope for a specific domain, like cryptography, is not defined or publicized.
Thank you for reading Cyber Builders. This post is public, so feel free to share it.
Let’s raise the bar - Certified Ethical Hack exam.
CEH stands for Certified Ethical Hacker. It is a certification in the field of cybersecurity that verifies an individual's skills and knowledge in identifying and exploiting vulnerabilities in computer systems and networks. The International Council of E-Commerce Consultants (EC-Council) issued the certification.
The CEH exam covers a wide range of cybersecurity topics, including but not limited to Footprinting, Scanning, Enumeration, Vulnerability Analysis, System Hacking, Malware, Sniffing, Social Engineering, DoS, Session Hijacking, Evading Security Measures, Web Server and Application Hacking, SQL Injection, Wireless Network Hacking, Mobile and IoT Hacking, Cloud Computing, and Cryptography.
According to Matt Walker, author of CEH Certified Ethical Hacker Practice Exams, Fourth Edition, CEH is a challenging but highly respected and valued certification. The Department of Defense recognizes CEH as suitable for Directive 8570 under DoDD 8140, so it's become a top certification for technicians. The four-hour, 125-question exam is challenging, but passing it is a meaningful addition to a security professional's skill set. In an interview, Walker warns against relying on memorization to pass the exam; candidates should absorb the necessary knowledge by networking, finding an infosec mentor, and self-studying.
So CEH looked like a perfect “high bar” test for GPT. So I used the CEH Practice Exams book to generate a 344 questions test. All questions have their correct answer; everything is stored in one big JSON file.
The diagram below describes the workflow I used.
There are several steps:
Step 1 - Use the book and its practice questions. Each question includes a text introducing the question and several answers (from 4 to 6). Some questions may consist of CLI commands to be explained. For example, this is a typical question.
A colleague enters the following command:
root@mybox # hping3 -A 192.168.2.x -p 80
What is being attempted here?
A. An ACK scan using hping3 on port 80 for a single address
B. An ACK scan using hping3 on port 80 for a group of addresses
C. Address validation using hping3 on port 80 for a single address
D. Address validation using hping3 on port 80 for a group of addresses
GPT-4 got it wrong. The correct answer is B - hping is to test if a host or application port is open; here, port 80 is for the web server, -A for ACK scan, and .x means to scan all IP addresses between 1 and 254 - and GPT-4 submitted A.
Step 2 - Build a JSON file of these questions to be able to loop over them
Step 3 - Loop over the question and ask GPT-4 to answer them. Those are straightforward instructions. The left block in dotted lines provides the prompt I used. For each answer, I am storing them in an answer file.
Step 4 - Loop over the answers provided and the correct answers and build stats and scores.
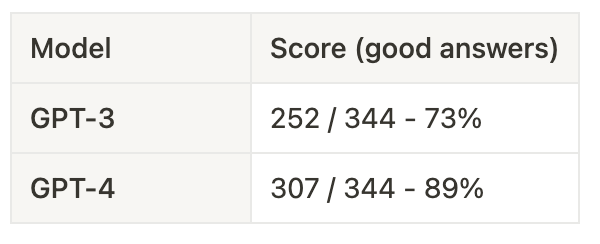
I tested against GPT-3 and GPT-4. The results are below.
On my god! 89% of good answers to a hacker exam. That’s another fantastic example of how much potential LLMs are for cybersecurity. The knowledge factored in the model is good, and GPT-4 scored very well on tough questions. Moreover, we can note the progress from GPT-3 and GPT-4.
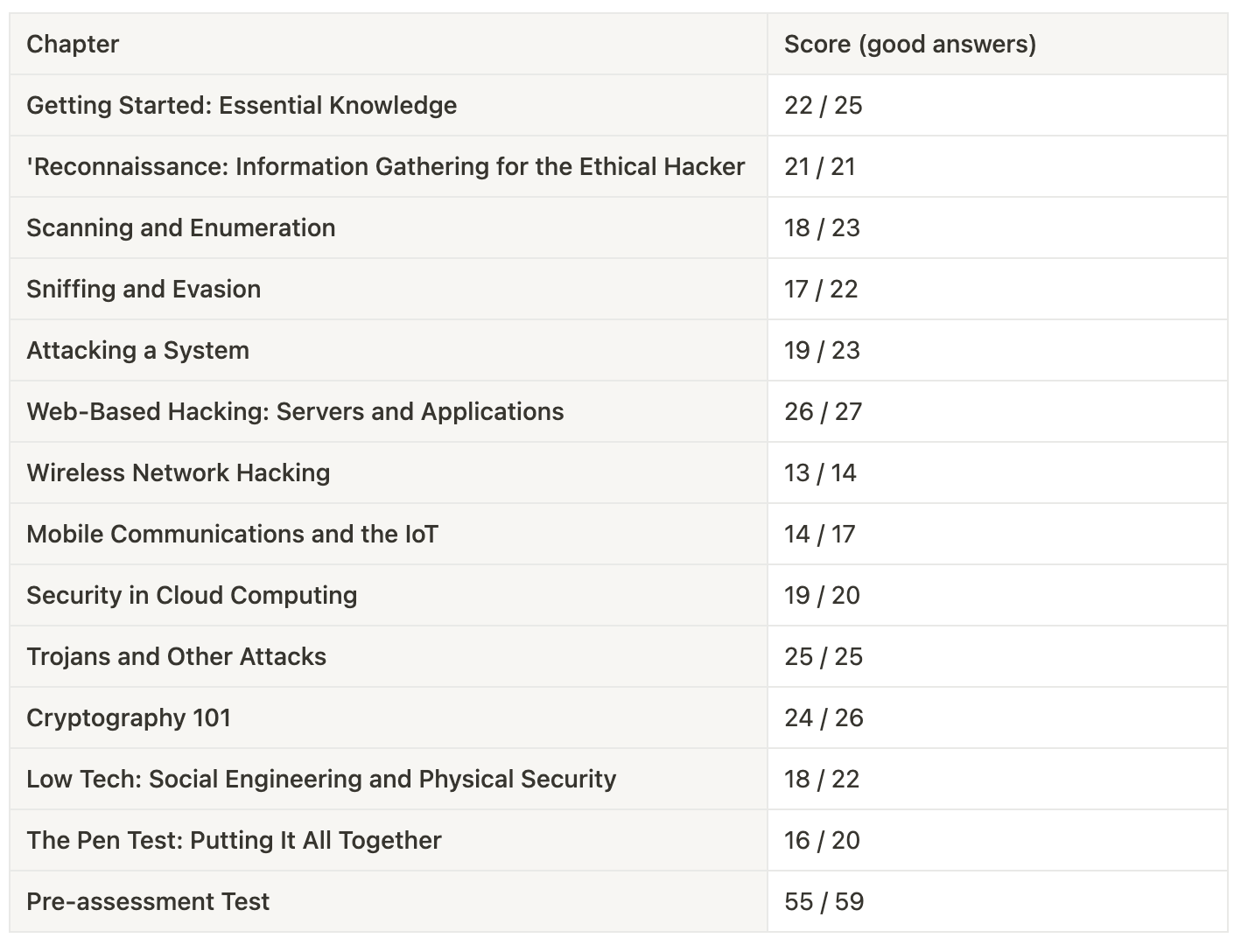
I wanted to know where he failed. So, I built the table below, zooming in on the result per chapter.
As you can read, there is no chapter where GPT-4 is terrible. It scored very well in all sections.
Final remarks
In conclusion, I'd like to highlight several key ideas.
Some caution needs to be taken with the results provided here. The CEH exam is popular; maybe GPT-4 was trained on other practice exams. GPT-4 may have also been trained on other security content, such as tutorials, online courses, or books. In that case, the tests here should be seen as a “knowledge retrieval” test, as I was querying a database. The tests done are not reasoning on a specific context.
LLMs within cybersecurity will be incredibly valuable in the future. From planning and prevention to detection and response, the possibilities for LLM integration in cybersecurity applications are vast and exciting. The impressive cyber knowledge in GPT-4 is just the tip of the iceberg regarding the potential of LLMs in this field.
Transparency is an indispensable aspect of any cybersecurity product. Beyond ensuring that users are informed about the product's features and capabilities, transparency also enhances trust and confidence. To achieve transparency, it is crucial to engage in careful product feature design that leverages the capabilities of LLMs. This will ensure that the product accurately reflects the data and insights generated by these powerful tools. As such, it is critical for the product's user experience to clearly distinguish between what comes directly from the LLMs and what is the result of other processing or analysis.
Only by providing users with a clear and accurate view of the product's inner workings can we build trust and ensure the success of our cybersecurity efforts.
The cybersecurity community needs a model rained on vetted reference documents corpus for the future. It will allow us to retrieve sources alongside answers. It will enable users to crosscheck provided texts with reference texts such as IETF, NIST, ENISA, or other public institutions’ publications.
Lastly, I am publishing this long post to get feedback. Please comment on the post below and share your ideas with me for five minutes.
I provided a lot of details about my research here. I used as a reference a book, and I am not allowed to republish its content. I don’t plan to release the code and the data.
If you liked the research, please subscribe below, and share on your Twitter / LinkedIn feeds or your Substack. Stay tuned for the following cyber builders.
Thanks for reading Cyber Builders! Subscribe for free to receive new posts and support my work.