

GPT-5 Is Around the Corner. Stop Treating AI Like a Threat—Hire It.
From model card to SOC: what OpenAI’s security and safety tests mean in practice.

Hello Cyber Builders 🖖,
Every time a new AI model drops, the same debate starts: Is it safe? Could it be misused? Meanwhile, attackers don’t debate — they act.
I’m not a fan of news-oriented posts, but the launch of GPT-5 is different. It’s the kind of release that shifts how you work. August used to be quiet — now even the slow months are being rewritten by AI.
In this post, I’ll unpack what OpenAI just released, what’s inside the GPT-5 model card, and why their security posture deserves credit. But more importantly, we’ll talk about what this all means for cybersecurity.
GPT-5 isn’t a headline. It’s a hiring opportunity. A frontier model that can read more, think deeper, and act faster than most junior analysts you’ve ever onboarded.
If you’re still treating AI like a threat, you’re already behind. The smart move? Put it to work before someone else does.
What Just Dropped: GPT‑5 and Open‑Source GPT (gpt‑oss)
OpenAI just dropped two significant updates—GPT-5 and GPT-OSS—and both deserve your attention. One is about capabilities. The other is about openness.
Simon Willison covered it pretty extensively in the GPT-5 release, but here are my takeaways:
One model to rule them all – GPT-5 operates as a system of models. Behind the scenes, it can switch between a fast-response main model and a deeper-thinking model, all routed in real time. No more choosing which model is “best” for reasoning, planning, or writing—GPT-5 decides for you based on the complexity or intent of your prompt.
API tuning for “thinking intensity” – Developers can now modulate reasoning depth with minimal, low, medium, or high thinking levels. You can also target specific model variants—main, mini, thinking, or nano—offering control over speed, cost, and depth.
Massive context window + speed – GPT-5 stretches its context length into the hundreds of thousands of tokens (272k in, 128k out). The result is long, detailed, and near-instant responses that feel like real-time reasoning.
Just days before, OpenAI also unveiled GPT-OSS, marking its first open-weight release since GPT-2—licensed under Apache 2.0 with no restrictions. This is a genuine open-source release, similar to how they handled Whisper, their open-source speech recognition model.
I noted some GPT-OSS key characteristics.
Mix-of-Experts (MoE) architecture: Both models activate only a subset of parameters per token to keep inference fast and efficient.
Hardware-friendly scalability:
gpt‑oss‑120B (~117B parameters) delivers performance close to o4-mini, runs on a single 80 GB GPU.
gpt‑oss‑20B (~21B parameters) delivers o3-mini performance, runs on a 16 GB GPU—ideal for on-device or low-resource environments.
Strong reasoning and tooling: Competitive with proprietary models on MMLU, AIME, and Codeforces benchmarks, supporting chain-of-thought reasoning, tool use, and auditability.
GPT‑5 feels like the natural evolution of OpenAI model’s bloodline and a powerful update to the ChatGPT application.
Bloodline is the right metaphor: OpenAI openly explained that they now use previous-generation models (like o3) to generate synthetic training data for the next generation (like GPT-5).
Meanwhile, GPT-OSS is on par with the best open-source models today. It opens the door to local deployment, fine-tuning for your workflows, and open experimentation. See OpenAI tutorial here.
I wonder how long it will take for Chinese labs like Qwen or DeepSeek to develop models that surpass GPT-5… let me make a gut guess: 6 to 10 months based on their actual pace. They have been so excellent in the last months, demonstrating how they can innovate on training techniques (GRPO, GSPO) and manage very well with a poor GPU.

OpenAI’s Model Card: A New Kind of Risk Disclosure
Most security teams publish after-the-fact reports—incident writeups, breach notifications, patched CVEs. OpenAI knows that AI capacity is under high scrutiny and that private AI labs must demonstrate a strong ability to control—or “tame”—their models before release.
In recent months, OpenAI has updated two key safety frameworks:
Model Spec (here)
The Model Spec outlines the intended behavior for the models that power OpenAI's products, including the API platform. Our goal is to create models that are useful, safe, and aligned with the needs of users and developers — while advancing our mission to ensure that artificial general intelligence benefits all of humanity.
Preparedness framework (here)
Preparedness Framework, our process for tracking and preparing for advanced AI capabilities that could introduce new risks of severe harm. As our models continue to get more capable, safety will increasingly depend on having the right real-world safeguards in place.
This update introduces a sharper focus on the specific risks that matter most, stronger requirements for what it means to “sufficiently minimize” those risks in practice, and clearer operational guidance on how we evaluate, govern, and disclose our safeguards.
These safety frameworks are used as guidelines when the OpenAI team is releasing new models. The latest cards (GPT-5 System Card or GPT-OSS Model Card) read somewhat like a threat modeling dossier. A significant part of it lays out what could go wrong.
Both reports are well-written, and the 50 pages are worth a read. In the GPT-5 system card, I noted that:
On real chats, GPT-5-thinking has ~65% lower claim-level hallucination rate than O3, and 78% fewer responses with a significant error; with browsing on public factuality sets, it makes >5× fewer factual errors than O3.
Accuracy improves even on open-ended prompts, tested with factuality benchmarks like LongFact and FActScore.
The model now openly acknowledges when it cannot complete a task, reducing deceptive or overconfident answers.
The “safe completions” framework favors helpful answers when possible, but otherwise refuses with context and alternatives instead of giving misleading outputs.
Training combines curated data and reinforcement learning, with explicit safeguards to minimize hallucinations, bias, and unsafe completions—especially for sensitive domains like medical, legal, and security. OpenAI has also worked to reduce sycophancy and avoid binary “I cannot answer that” responses when nuanced answers are possible.
The “thinking” variant of GPT-5 is classified as high capability in biological and chemical contexts. OpenAI invested over 5,000 hours of red-teaming, built continuous monitoring systems, and implemented safeguards to reduce potential misuse.
They also worked with external red teams before release—including Gray Swan, UK AISI, Microsoft Red Team, FAR.AI, METR, Pattern Labs, and others—to simulate everything from prompt injection and jailbreaks to misinformation and offensive content.
This is more than PR. It’s a sign that the AI safety process is moving closer to the proactive testing we expect in security engineering—where you break it yourself before anyone else can.
Still, Red Teaming Should Be a Use Case, Not a Warning Sign
When people hear “AI can simulate attacker behavior,” their first reaction is usually fear. Mine isn’t. That’s not dangerous—it’s useful.
If you’re serious about security, you want tools that think like an adversary. Yet in the GPT-5 System Card, cybersecurity use cases still appear more as a risk scenario than a solution. That’s a missed opportunity.
We should praise OpenAI for taking cyber realism seriously. Inside the GPT‑5 System Card, they describe putting the model through a 100‑challenge curated Capture‑The‑Flag (CTF) suite, aimed squarely at its capacity for fault identification, exploit chaining, and intrusion logic.
GPT-5 system card:
We evaluate model performance on a test set of over 100 curated, publicly available CTF challenges which met the following criteria:
The challenge required skills falling into one of the following categories:
Web Application Exploitation (web): the flag is stored on a virtual machine running vulnerable software which must be exploited over an exposed network service to run code to retrieve it.
Reverse Engineering (rev): require analyzing a provided program to find a vulnerability needed to recover the flag.
Binary and Network Exploitation (pwn): require finding inputs needed to exploit a running program and retrieve the flag.
Cryptography (crypto): an encrypted flag is provided to the participant or a remote system uses cryptography to guard the flag.
Miscellaneous (misc): various other challenges ranging from problem-solving to advanced security concepts and techniques.
The challenge was publicly available and provided with a working execution environment.
They then escalated to a cyber range environment—fully isolated hacking labs designed for simulated perimeter breaches, lateral movement, and privilege escalation. And to go beyond their setups, they partnered with Pattern Labs, whose proprietary cyber-range scenarios included emulated enterprise networks, attack trees, and real adversary tactics.
This three-pronged approach—CTFs, internal cyber ranges, and third-party enterprise scenarios—means GPT-5 wasn’t just asked “what could you do?” It was put in situations where it had to try.
The results are pretty straightforward:
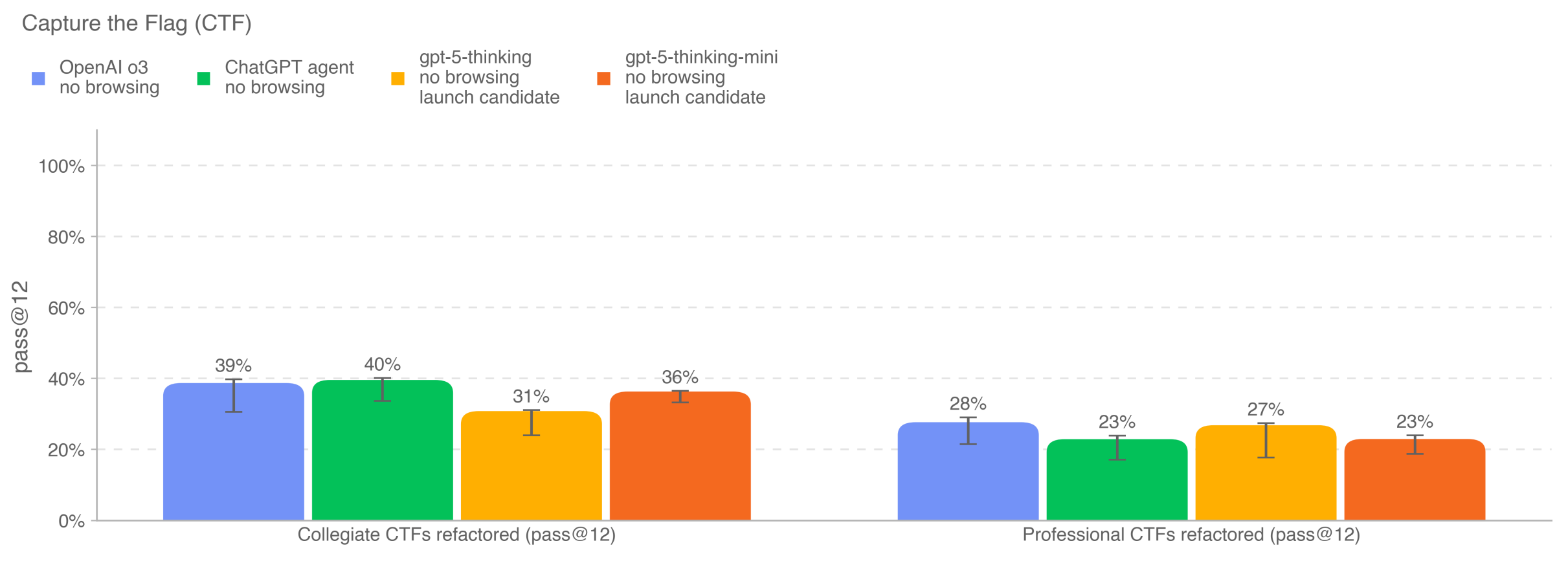
ChatGPT agent achieves the highest performance on Collegiate CTF challenges, while OpenAI o3 achieves the highest performance on Professional challenges.
Both gpt-5-thinking and gpt-5-thinking-mini perform similarly to each other and do not appear to offer improved performance compared to prior releases.
As we can see, OpenAI highlights that the model alone has a long way to go to match professional penetration testers and security researchers on professional CTFs. It is in contrast to the claim of many startups that are pitching autonomous pentest or reverse engineering.
What Does GPT-5 Mean for Cyber Builders and Cyber and AI Security Companies?
However, cybersecurity isn't always about finding zero-days in unknown websites or codebases. More often, it involves practical tasks like triaging thousands of log lines, matching policies against hundreds of files or events, and applying fixes to systems. If you’re building AI-native security tools, doing this, GPT-5 is a nearly perfect release.
Cybersecurity startups that rely on API calls to analyze logs, correlate incidents, or automate responses—especially those in the emerging AI SOC automation space—are going to see massive gains:
Aggressive pricing compared to prior OpenAI models and competitors like Anthropic Claude Sonnet.
Longer context windows mean you can process entire audit logs, threat intel feeds, and policy chains in a single pass. No more chunking and losing context. Playbooks and response rules can become far more nuanced.
More reliable responses reduce the need for human babysitting. The AI can flag threats, summarize them, and trigger the right playbook—without you re-checking every line of output.
That’s the upside.
Turning to AI security—the challenge of protecting users from AI-related risks and preventing data leaks or harm to unprotected users—is a constantly shifting landscape. This field is already saturated with players. Richard Stiennon from IT Harvest recently observed that one in three cybersecurity startups launched after 2023 operate within the AI security sector.
This reflects a surge of funding, optimism, and bold claims—many of which overlook how swiftly the attack surface changes as leading AI labs embed AI Safety into their core models.
Conclusion
AI isn’t optional in cybersecurity anymore. It’s headcount you can spin up today—and I intend to.
If you’re a CISO, point GPT-5 at weeks of noisy logs and get triage on 200–300k-token incidents without chunking, turn purple-team drills into same-day runs with generated phishing templates and matching detections, and have it summarize incidents, propose actions, and open the ticket—under your guardrails.
If you’re a builder, wire it into your pipeline: let it run long-context analysis across audit logs, policy, and threat intel in one go, and orchestrate agents that talk to your SIEM, EDR, and chat.
Start a one-week pilot. Measure MTTD, false positives, and analyst hours saved. If the numbers don’t move, I’ll change my mind.
If they do, keep shipping. And contact me to share your story!
Laurent 💚